안녕하세요. 가희배 3회 코딩테스트 문제들을 셋팅하면서 xml 형식을 파싱해야 되는 일이 생겼는데요. 파이썬에서 이를 간단하게 할 수 있었어요. xml.etree.ElementTree를 이용해서 간단하게 작성해 보았습니다.
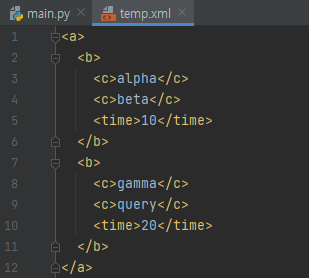
먼저, temp.xml에는 위와 같은 내용들이 저장되어 있어요. html도 사실 보면 저 구조와 크게 다를 바가 없습니다. 이 친구를 읽어서, 태그에 달려있는 값들만 뽑아오도록 할게요.
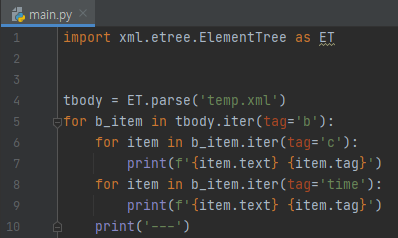
먼저, ET.parse를 통해, temp.xml에 있는 내용들을 읽어서, tree화 시킵니다.
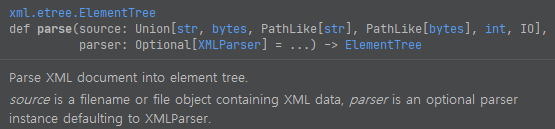
함수 설명은 위와 같은데요. XML document를 element tree로 변환한다고 되어 있어요. 다음에, iter를 돌릴 건데요. iter 함수를 썼어요.
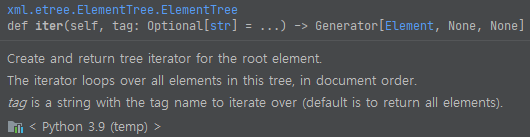
레퍼런스 설명을 보면, tree iterator를 리턴한다 되어 있어요. root element로부터요. 만약에 tag 이름을 주면 해당 태그만을 가져오게 됩니다. 이 함수의 내부를 보면 어떻게 동작하는지를 간파하실 수 있는데요.

self가 조건을 만족시키면, self를 yield 시켜요. 그리고 children, 자식들을 돌면서, 조건을 만족하는 게 나오면 또 yield를 시켜버립니다. 이것이 재귀적으로 구현이 되어 있는데요. 트리 순회를 할 때 많이 보이는 패턴 중 하나이니 익혀두시면 좋을 듯 싶어요.
이제 코드와, parseTree를 보면서 설명해 보도록 할게요.

먼저, tbody는 xml 전체의 parseTree였어요. tbody.iter(tag='b')는 이터레이션을 도는 도중에, tag가 b인 것만 얻어오게 됩니다.
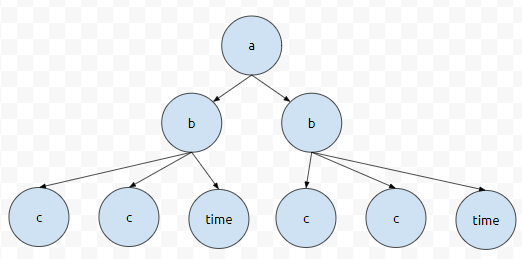
그러면 먼저 a부터 출발할 겁니다. a는 아니니까, 자식들을 볼 텐데요. a의 자식이 b입니다.
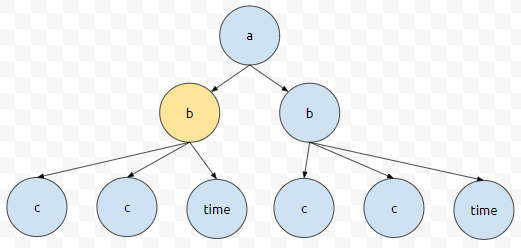
그러니, b_item은 노란색 부분의 정보가 뽑히게 될 겁니다. 이제 우리는 이 정보에서 뭘 뽑을 것인가? tag가 'c'인 것을 뽑아버릴 거에요. 그러면 b_item의 root가 노란색으로 칠한 부분이니까 노란색 부분 먼저 탐색하고 c, c, time 순으로 search 할 겁니다. 일단, 노란색으로 칠한 것은 'c'가 아니므로, 자식으로 들어갑니다.
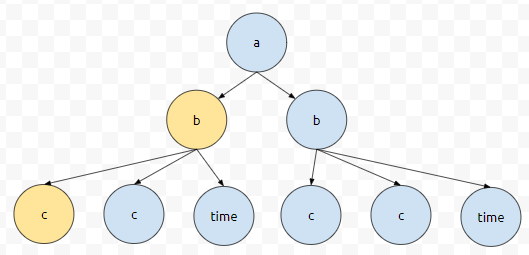
이제, 'c'가 나왔습니다. 그러므로 이 정보를 뽑아냅니다.
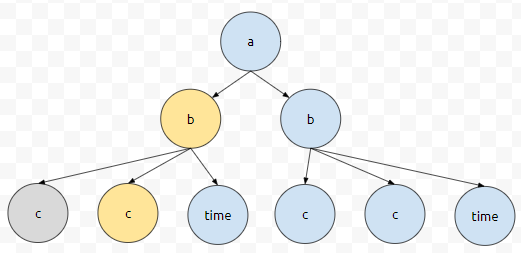
다음 iteration을 돌면, 또 tag가 'c'인 것이 나옵니다. 이에 대한 정보를 또 뽑아냅니다. 그 다음에는 time으로 가는데요. tag가 'c'가 아니므로 iteration은 끝나게 됩니다.
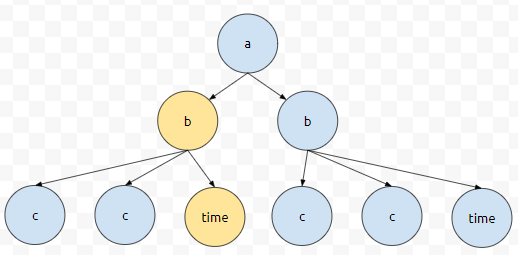
반대로, tag가 'time'인 것을 탐색하는 것은 어떨까요? b, b, c, time 순으로 순회하게 됩니다. 이 중에 tag가 time인 것은 4번째에 순회한 것이므로 time node에 있는 정보를 얻어오게 됩니다.

이제 5번째 줄을 봅시다. tbody가 a에 대한 정보라고 했어요. 한 번 loop를 돌면, 그 다음 'b'로 넘어갈 건데요.
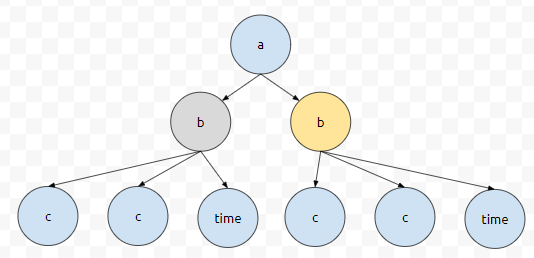
이 때 b 밑에 있는 c, c, time을 순회하고 난 다음에, a의 2번째 child인 b로 넘어가게 됩니다. 당연하게도 c, c, time은 tag 이름이 b가 아니므로, 순회는 되지만 무시됩니다. 동작 원리는 이 정도만 이해하셔도 무난해 보입니다.
'코딩 > 파이선' 카테고리의 다른 글
| 파이썬 dictionary get 함수와 key가 없을 때 default 값을 얻는 법을 알아봅시다. (2) | 2022.04.29 |
|---|---|
| python set 교집합 차집합 합집합 대칭 차집합을 구해 봅시다. (0) | 2022.04.13 |
| python itertools에 있는 product permutations combinations 함수를 알아봅시다. (0) | 2021.12.18 |
| 파이썬 heapq 모듈을 이용해서 priority queue 를 사용해 봅시다. (0) | 2021.11.05 |
| 파이썬 packing과 unpacking에 대해서 간단히 알아봅시다. (0) | 2021.10.21 |


최근댓글