오프라인 쿼리. ps 하면서 한 번 쯤은 들어보셨을 법한 말입니다. 무엇을 오프라인으로 처리한다는 것일까요? 사실 잘 모르겠습니다. 대신에, 하나의 문제에 대해서 생각해 보면서 어떤 것이 오프라인 query 인지 대충 감만 잡도록 하겠습니다. 그냥 관점만 보셔도 됩니다. ps를 하는데 막 오프라인이 뭐냐고 묻진 않을 거니까요. 그거보다는 어떻게 효율적으로 해결할지 생각하시는 것이 더 중요하지 않을까 싶습니다.
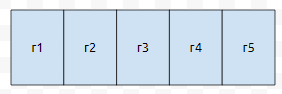
배열이 이런 식으로 있습니다. 여기서 r1, r2, r3, r4, r5는 해당 위치로부터 얼마나 떨어진 거리까지 영향을 미치는지에 대한 것입니다. 마나커 알고리즘을 한 번 보셨다면, 이해가 가실 겁니다. 문제는, 이것이 기본적인 마나커에서 +3 ~ +4가 된 이유는, 이것을 처리하는 아이디어가 어렵기 때문입니다.

이 쿼리가 10만개가 들어옵니다. 어떻게 해결해야 할까요? 이 쿼리를 잘 관찰해 봅시다. s에서부터 시작하는 팰린드롬의 길이가 최소 K 이상이 되려면 어떻게 되어야 할까요? 일단, 길이 2짜리, 4짜리 팰린드롬도 고려를 해야 하니, ababa가 있다면, 중간에 #과 같은 문자열을 추가해서 #a#b#b#a#a# 이렇게 전처리를 하셨을 거라고 생각합니다.

여기서, 마나커 알고리즘을 적용한 결과가 1번째 줄의 결과입니다. 여기서 #을 넣은 것은 길이가 짝수인 경우를 고려하기 위해서입니다. 즉, manacher M 배열은 인덱스가 짝수일 때 '#'입니다. 해당 위치를 중심점으로 해서 팰린드롬을 만들 건데, #을 제외한 문자로 길이가 len인 것을 만들 수 있으면 len이 채워집니다. 예를 들어서, 8번째 위치를 보면 아래와 같이 되어 있습니다.

제가 황금색으로 칠해놓은 것을 기준으로 5짜리 팰린드롬을 만들 수 있습니다. 그런데 #을 제외하면 2이므로 2가 채워집니다. 홀수인 경우에는 어떤가요? 해당 위치를 중심점으로 해서 최대한 팰린드롬을 길게 만들었을 때, #을 제외한 문자의 갯수로 보면 됩니다. 예를 들자면, 9번째 위치를 보면 아래와 같이 만들 수 있습니다.
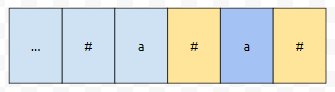
3개까지 만들 수 있는데, 여기서 #을 제외한 문자는 1개가 있으므로 1이 됩니다. 여기까지는 쉽게 할 수 있습니다. 문제는 쿼리를 어떻게 처리할 것이냐는 것입니다.
관찰을 해 보겠습니다.

쿼리에 나오는 s를 노란색으로 칠한 부분이라 해 보겠습니다. 그리고 K는 팰린드롬의 길이를 의미하는데요. 만약에 그 길이가 2라면 어떨까요? 제가 군청색으로 칠한 부분에 노란색 location까지 커버 된다는 정보가 있어야 합니다.
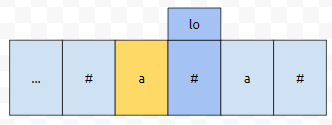
이 값을 lo라고 합시다. 만약에 lo보다 작은 데 까지 커버 된다고 하면 어떨까요?
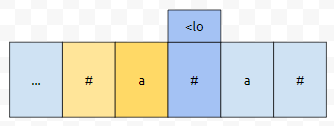
그 경우에는 ..aa..를 만들 수 있으므로, 길이가 2인 것을 만들 수 있게 됩니다. 즉, 해당 상황을 단순화 시켜 보면

lo부터 시작했을 때, 팰린드롬의 길이가 2라면, lo+1번째가 커버하는 왼쪽 위치가 lo보다 작거나 같아야 합니다.
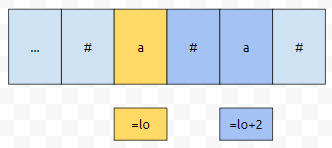
lo부터 시작했을 때, 팰린드롬 길이가 3이라면, lo+2까지 갔을 때, 커버하는 왼쪽 위치가 lo보다 작거나 같아야 합니다. 당연하게도 3은 2보다는 크니까, lo+2가 커버하는 왼쪽 값이 lo보다 작거나 같다면 lo부터 시작하는 팰린 길이가 2보다 크거나 같다는 조건을 만족합니다.
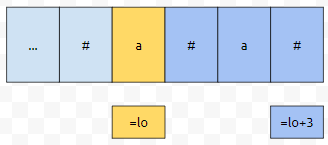
길이가 4가 되려면, lo+3까지 갔을 때, 커버하는 왼쪽 위치가 lo보다 작거나 같아야 합니다. 이런 식으로 계속 확장하다 보면, 아래와 같은 결론에 도달함을 알 수 있습니다. 즉, 쿼리에서 s K가 들어온 경우에, 우리는 아래와 같은 질문에 대해서 빠르게 답을 해야 하는구나.
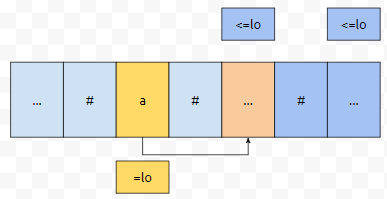
특정한 위치보다 우측에 있는 범위에서, 커버하는 값이 lo 이하인 가짓수가 얼마인가? 특정한 위치는 lo+K-1입니다. 이 때, K는 1이상일 때 이야기입니다. 그리고, 이 lo 값은 #이 들어가 있음을 고려해서 계산하면 될 겁니다. 그러면 우리는 해당 위치에서부터 왼쪽 부분 어디까지 커버하는지를 미리 채워놓아야 합니다.
거기까지 오셨다면, 우리는 아래와 같은 문제로 바꿀 수 있습니다.

대충 2차원 세그먼트 트리 각이 보입니다. 그런데, 문제를 쭉 분석해 보니, 쿼리는 (x, u) 쌍으로 주어졌습니다. 조금 더 관찰해 보면, x가 큰 경우부터 작은 경우까지 쭉 훑으면, 그냥 1차원 세그 트리로 간단하게 처리할 수 있음을 알 수 있습니다. 왜냐하면 x1 < x2일 때, 구간 [x2, n-1]은 [x1, n-1]에 속하기 때문입니다. 즉, 저런 Q가 10만개 정도 들어왔을 때, x 내림차순으로 정렬해 버리면 됩니다. 게다가, 문자열이 업데이트 되는 이상한 현상도 일어나지 않았습니다.
아 그러면 온라인을 업데이트라고 봐도 되나요? 이 글에서는 그것이 중요한 키가 아닙니다.
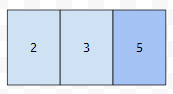
예를 들어 x = 2, u = 4 쿼리가 들어왔다고 해 봅시다.
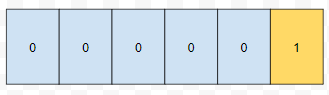
그러면 쿼리가 들어왔으니, 5를 합을 처리하는 세그먼트 트리에 넣습니다. u가 4이니, 0부터 4까지의 누적합을 구하면 되는데, 0임을 알 수 있습니다. 다음에 x = 2, u = 5 쿼리가 들어왔다고 하면 어떨까요?
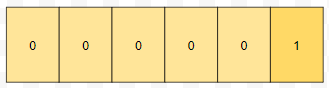
그냥 부분합을 구하면 됩니다. 다음에 x = 1, u = 3이 들어온 경우에 index 3의 값을 하나 증가시킵니다.
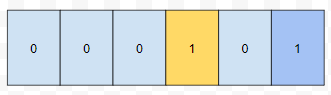
end. 우리는, 쿼리가 들어오는 것을 적절히 변형하고, reordering을 해서 우리가 풀기 쉽게끔 바꾸었습니다. 그러니, 정렬을 생각보다 많이 씁니다. 이를 흔히 오프라인으로 쿼리를 처리한다고 합니다. 들어오는 순서대로 처리한 것이 아니라는 게 중요한 포인트입니다. Mo's algorithm. 즉, 평방 분할은 쿼리 순서를 다시 재배치 해서 푸는 문제 중 하나인데요. 이것을 공부하신다면, 아 이게 오프라인이구나를 알 수 있을 겁니다.
'자료알고 > 알고리즘' 카테고리의 다른 글
| 백준 최소 환승 경로 : 허브와 노드를 생각하자. (0) | 2021.02.07 |
|---|---|
| functional graph 에서 사이클을 어떻게 묶어낼까요? (0) | 2021.01.26 |
| 정점 분할 : 노드를 상태에 따라 여러 개로 쪼갠다. (2) | 2020.12.29 |
| 수학적 귀납법을 활용하여 문제를 풀어봅시다. (0) | 2020.12.24 |
| 백준 1060번 구간 : 후보해를 추린다. (0) | 2020.12.03 |


최근댓글