C++의 sort는 어떻게 O(nlogn)의 복잡도가 보장될 수 있을까요? 저번에 compare 함수가 항상 True를 리턴할 때에 어떤 일이 일어나는가? 편에서 이 함수를 뜯은 적이 있었습니다. 그 기억을 되살려서 보도록 하겠습니다. Quick sort는 pivot을 어떻게 선택하느냐가 중요하다고 했어요.
저번에 median 값을 가지고 pivot값을 생성한다는 것을 알 수 있는데요. 이 방법을 저격하는 데이터가 있다는 것이 알려져 있어요.
그러면 이 방법을 어떻게 해결할까요? nth_element에도 적용되는 기법 중 하나인데요. 호출 깊이의 제한을 둡니다.
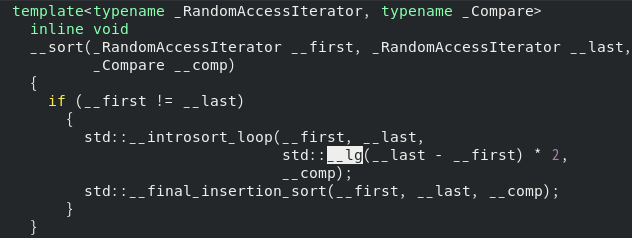
first와 last가 다른 경우, __introsort_loop를 호출합니다. 그런데, 이것은, 3번째 인자에 이상한 __lg(__last - __first)의 2배를 곱한 값을 넘긴다는 것을 알 수 있습니다. __lg(x)는 밑이 2인 log(x)의 값을 돌려주는데요. 일례로, x가 2^20이라면 20을 돌려줍니다. 만약에, __last - __first가 2^20이라면, __introsort_loop에 넘기는 3번째 인자의 값은 40이 됩니다.

이제 LOOP 함수를 봅시다. 여기서 중요한 것은 __depth_limit가 0이 되었을 때의 동작인데요. 이 때 __partial_sort를 호출합니다.

그렇지 않으면, _depth_limit를 감소시키고, __introsort_loop를 호출합니다. 일단 이 부분에 대해 먼저 이야기 해 보도록 하겠습니다. partition_pivot은, 전체 배열에서 피벗값을 뽑은 다음에, 그것을 기준으로 2분할을 하는 메서드입니다. 그런데, 그 범위가 __first부터 __last입니다.
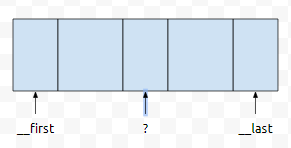
그러면 pivot을 기준으로, 어떻게 잘 나뉠텐데, 이 중 뒤에 부분을 재귀 호출합니다. 앞에 부분은 필요 없을까요?

아뇨. 그것은 아닙니다. 앞에 부분도 sort를 하긴 해야 할 겁니다. 일단 보라색 부분을 처리하기 위해서, __depth_limit에 1을 뺀 다음에, 이 값을 넘깁니다. 대충 D-1이라고 해 봅시다.

그러면, 노란 부분을 partical_sort를 할 때 depth는 D-1이 될 겁니다. ?의 값이 아마도 __last가 될 거고요. __first에서 __last까지를 표현한 것은 노란색 부분이 될 거에요. 여기서 __cut을 찾아서 분할해 봅시다.

depth_limit는 하나 감소합니다. D-2인 상태에서 분할을 해서, 맨 아래에 있는 사각형 2개로 divide 되었다고 해 봅시다. 그러면 보라색 부분을 introsort 하기 위해서, 3번째 depth 인자가 D-2가 들어갈 거에요. 그러면 위에 D-1이라고 써져 있는 보라색 사각형은 어떨까요?

오른쪽 부분도 마찬가지로 보면, 어떠한 구간이 2개의 구간으로 분할이 될 때 마다 depth_limit가 하나씩 감소한다는 것을 알 수 있습니다. 어떠한 구간 L이 pivot으로 인해 구간 A와 구간 B로 분할되었다고 해 봅시다. 이 때, L의 자식은 A, B라고 할 수 있습니다.
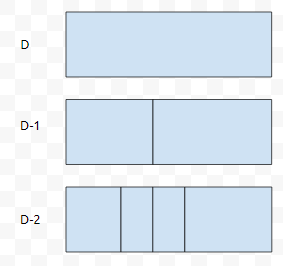
이 상황을 간단하게 도식화 하면 위와 같이 나타낼 수 있어요. 어떠한 구간 L이 A, B로 나누어 지려면, pivot을 가지고 구간 L 전체를 탐색해야 합니다. 이로 미루어 보았을 때, D인 상태를 D-1로 바꾸려면 배열의 크기만큼, D-1을 D-2로 바꾸려면, 또 배열의 크기만큼의 단위 연산을 수행하면 될 거에요.
결국, 배열의 크기에 D를 곱한 만큼 분할을 하게 되는데, D의 값이 밑이 2인 log(n)에 비례하므로, nlogn이 됩니다. 네. 분할까지 고려했을 때 말입니다.
그런데 정말 O(nlogn)이 보장될까요? __partial_sort를 보도록 하겠습니다.
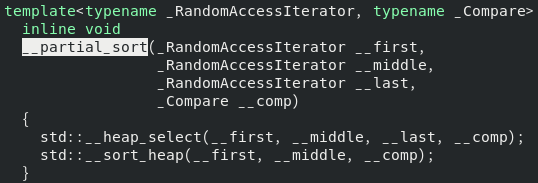
그러면, 이것은 중간에 __heap_select와 __sort_heap을 호출하고 있는데요. HEAP_SORT의 복잡도는, 구간의 크기가 m일 때 O(mlogm)입니다. 그래서 O(nlogn)이다라고 말하면 조금 심심할 듯 싶고요. 대충 D만큼 들어갔을 때 __partial_sort의 단위 연산은 총 몇 번이나 일어났을까요? 이건 조금 까다롭습니다.

y=x와 y=xlog(x)의 그래프를 그려보면 위 그림과 같습니다. x에 밑이 로그 2인 x를 곱한 함수 g(x)의 도함수를 구해보면 아래 그림과 같습니다.
x>=1일 때, 기울기가 계속 증가하면서 도함수의 값도 양수입니다. 그렇다면, 아래로 볼록하다는 이야기가 됩니다. 아래로 볼록한 그래프 중 하나는 y = x^2가 있습니다.

그러면, A+D = B+C이고, 1<=A<B<C<D일 때, f(A)+f(D)가 더 클까요? f(B)+f(C)가 더 클까요? A=1, B=2, C=3, D=4를 넣어보시면 명확하게 보이실 겁니다. 눈으로 보아도 f(A) + f(D)가 더 크다는 것을 알 수 있어요. 즉, pivot이 1개씩만 분할되는 경우가 __particial_sort의 총 단위 연산 횟수가 최악에 가깝게 된다는 것을 알 수 있습니다.

그러면, 노란색 부분을 heap sort 할 때 복잡도를 구해봐야 겠네요. n이 10^5, 10^6 정도 되는 큰 수라면, D << n이므로, 사실상 n-D는 n으로 근사할 수 있습니다. 힙 정렬은 O(nlogn)이므로, partical_sort의 연산 무게도 nlogn입니다. pivot을 나누는 것도 앞의 상수 제거하면 nlogn입니다.
따라서, c++의 sort 함수, 인트로 정렬은 최악의 경우에도 O(nlogn)의 복잡도를 가집니다.
'레퍼런스 > 분석' 카테고리의 다른 글
| java hashset은 key의 해쉬 코드가 모두 같을 때 최악 복잡도가 어떻게 될까요? (6) | 2019.12.18 |
|---|---|
| 왜 java에서는 equals 메서드를 오버라이드 하면 hashCode 도 같이 해야 할까요? (2) | 2019.12.15 |
| c++ unique 함수 : 정렬을 먼저 해야 중복이 제거된다. (2) | 2019.11.28 |
| c++ sort 의 비교함수가 true만 리턴할 때 어떤 일이 일어날까요? (8) | 2019.11.12 |
| c++ string c_str 함수 : string을 char *로 바꿔봅시다. (6) | 2019.11.11 |


최근댓글