이 포스트를 이해하기 위해서는, Hash 자료구조에 대한 이해가 선행되어야 합니다. 만약에 이에 대한 이해가 없다면, 이 포스팅을 보고 오시는 것을 강력하게 권해드립니다. 흔히 많은 책에서 equals를 오버라이딩 하면, hashCode를 같이 오버라이딩을 하라고 합니다. 왜 그런지 천천히 알아보도록 하겠습니다. Dog 클래스입니다.

오늘은 이 클래스만 보고 이야기를 해 보도록 하겠습니다.

먼저 hashSet에 item을 하나 넣었다고 가정해 봅시다. 그러면 HashSet의 add 메서드가 hashMap의 put 메서드를 호출합니다.

put은 putVal 메서드를 호출하는데요. 이 때, 1번째 인자로 hash(key)를 넣습니다. 이 함수의 내부를 봅시다.

hashSet에 add한 key 객체가 hashCode를 오버라이딩 하고 있으면, 그 메서드를 호출합니다. 예를 들어 Dog 객체를 넣었습니다. key는 Object화 된 것이긴 합니다. 그런데 사실, Dog에서 정의한 hashCode가 실행됩니다. 이게 왜 그렇게 일어나는지는 다형성을 이해하면 좋을 듯 싶어요.
만약에 Dog에 hashCode가 정의되어 있지 않다면, 부모에 정의되어 있는 hashCode를 쓰게 되는데요. Dog가 Object만 상속받고 있다면 아래와 같은 메소드가 수행이 될 겁니다.
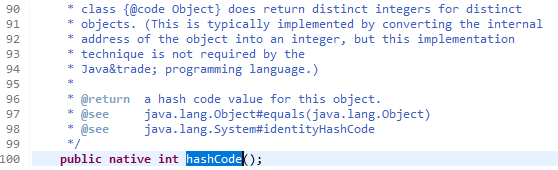
Object의 hashCode. 이것은 객체가 다르다고 다른 값이 나온다는 보장은 없습니다. 당연하게도 이 포스팅에서 설명을 했습니다. 하지만, 다른 값이 나올 가능성은 꽤 큽니다. 예를 들어, equals로 name과 나이가 같으면 같은 객체다. 라고 정의가 되었다고 해 봅시다.

이 두 친구 hashCode값을 찍어보면 다른 값이 나오는 경우도 있을 거에요. 그러면 이게 어떤 영향을 끼칠까요?
putVal 메서드를 보면 hash 값이 Key의 hash값임을 알 수 있어요. 그러면 이 값이 어디에 쓰이는지는 추적해 봅시다.

먼저 i값이 있습니다. i값은 (n-1)&hash로 판별이 되는데요. 살짝 바꿔보면 i는 hash&(i-1)로 판단을 할 수 있습니다. 이 hash값은 key의 hashCode 값입니다. 그리고, n-1은 무엇인지 잘 모르겠지만, n-1이 15, 31, 63, ... 이런 식으로 증가하면 (n-1)&hash는 각각 모듈러 16, 32, 64, ... 등으로 볼 수 있습니다.
해시 값이 나왔을 때, 그것을 버킷에 분배하는 함수 정도라고 생각하시면 편합니다.

이것을 그림으로 그리면 위와 같습니다. 여기서 h 함수는 우리가 흔히 알고 있는 hashCode의 리턴 값입니다.
그러면 왜 age와 name이 같은 두 객체가 왜 다른 버킷에 넣어졌을까요? 이유는 간단합니다. [3, "gahui"] 라는 객체가 있었다고 해 봅시다. 그리고 이것의 hashCode 값이 18이였다고 해 봅시다. 버킷 갯수가 16이라고 한다면, f(h([3,"gahui"]))의 값은 f(18) = 2입니다.

다른 버킷에 [3,"gahui"]가 있다고 해도, [2]에 [3,"gahui"]가 존재하지 않습니다. 따라서, [3, "gahui"]가 버킷 2번에 추가됩니다.

만약에, [3, "gahui"]의 hashCode값이 34이면 어떨까요? 버킷 갯수가 16인 경우, f(34)는 2입니다.

여기서, 634번째 if문에 걸립니다.

p.key와 key가 같은지 다른지는 중요하지 않습니다. 2번째 조건을 보면 key가 null이 아니고, key.equals(k)가 참인지가 중요하다는 것을 알 수 있는데요. Dog 객체는 equals를 오버라이드 했습니다. 그에 따르면 age랑 name이 같으면 equals가 참이다. 라는 것을 리턴하게끔 되어 있었습니다.
그런데 [3, "gahui"]를 넣는다고 했어요. 2번째 조건을 만족하기 때문에, 새롭게 덮어 씁니다.

이는 653번째 줄을 보시면 알 수 있어요. e = p; 였기 때문에, 일단 e값은 NULL이 아닙니다. 그리고 onlyIfAbsent는 putVal의 4번째 인자로 들어오는데, false 값으로 들어왔기 때문에, 656번째 줄이 수행됩니다. 이것은 Val 값을 덮어쓰는 것입니다. 저 4번째 인자가 true로 들어오는 경우에는 putIfAbsent를 호출했을 때이고요.

그러면, 해당 bucket에 equals로 걸리는 게 있을 때에는 추가가 되지 않겠네요. a와 b가 equals로 비교했을 때 같은 객체라도, hashCode 값이 다르다면, 서로 다른 버킷에 할당이 될 가능성이 있습니다. 함수 f(x)가 있을 때, f(a)와 f(b) 값이 존재한다면, f(a)와 f(a)가 같다는 것은 항상 참이지만, f(a)와 f(b)가 같은 건 항상 참이 아닙니다.
그렇기 때문에, 의도치 않은 결과가 나올 수 있어요. 예를 들어 [3, "chogahui"]는 분명히 있는데, 없다고 할 수도 있을 거에요. 따라서, equals랑 hashCode랑 같이 정의해주는 것이 좋습니다.
'레퍼런스 > 분석' 카테고리의 다른 글
| java copyOf 메서드 : 배열을 복사한다. (5) | 2019.12.27 |
|---|---|
| java hashset은 key의 해쉬 코드가 모두 같을 때 최악 복잡도가 어떻게 될까요? (6) | 2019.12.18 |
| 인트로 정렬 : c++의 sort는 왜 최악의 경우에도 빠르게 동작하는가? (4) | 2019.12.07 |
| c++ unique 함수 : 정렬을 먼저 해야 중복이 제거된다. (2) | 2019.11.28 |
| c++ sort 의 비교함수가 true만 리턴할 때 어떤 일이 일어날까요? (8) | 2019.11.12 |


최근댓글