사실, 이런 류의 기능을 하는 함수는 구현을 해야 할 일이 있을 겁니다. 여기에서는 optimize 생각 안 하고, 어떻게 빠르게 구현을 할 지, 패턴 정도만 이야기 해 보도록 하겠습니다. 3 종류의 쿼리가, Q개 들어온다고 생각해 보겠습니다.

이 때, insert 하는 위치와, delete 하는 위치 모두는 vaild 하다고 생각해 봅시다.
먼저, 구조체를 하나 정의하기 전에, 어떤 구조가 적합한지 먼저 생각해 봅시다. 사실, 적절한 자료구조가 있습니다. i번째 위치를 빠르게 찾는다. [s, e]번째 위치에 있는 원소 item들을 모두 delete 하는 것 또한, s번째 item을 찾고, e번째 item을 찾기만 하면 됩니다. 그러면 kth를 빠르게 찾을 수 있는 구조면 좋은데요. 그 중 하나는, skip_list입니다.
그런데, 만약에 skip_list를 구현할 시간조차 안 된다면 어떻게 하면 좋을까요? 포기를 해야 할까요? 그것은 아닙니다. 기본 자료구조를 생각해 보셔야 하는데요. list나 array는 정말 흔히 쓰는 구조입니다. 이 둘 중에서 더 적합한 구조는 어떤 것일까요? List는 delete가 일어나고, insert가 일어나는 i번째 위치를 빠르게 알아낼 수 없습니다. skip_list면 가능하지만요. 그렇기 때문에, 공간도 줄여야 하고, locality도 확보를 해야 하는데요. 이 둘을 적당히 잘 만족하는 것은 배열입니다. vector의 insert와 erase를 구현을 해 볼 겁니다.
그러면, 대략적으로 구조는 위와 같이 나오겠네요. 작성해야 할 메서드는 3개인데요. insert(loc,item), erase(loc), erase(s,e) 이렇게 3개입니다. 그런데, add가 될 때, size가 늘어나기 때문에, capacity를 초과할 수 있습니다. 이 처리를 하기 위해서는, grow 메서드도 따로 구현을 해 주어야 합니다.

저는 grow_rate의 값을 2로 잡겠습니다. grow 과정에서는 capacity와, 새로운 배열을 할당하므로, arr의 주소만 바뀌면 됩니다. 왜 굳이 이런 걸 구현하냐. 자료구조에 나올 거를. 이라고 물으신다면, 구현에서도 많이 나오기 때문입니다.
먼저 add를 생각해 봅시다. 일단 add가 된다면, size가 하나 증가할 겁니다. 그러면, 증가 후의 size는 size+1이 됩니다.

그러면, 먼저 lo가 add 되기 전에 배열 size보다 크다면 vaild 하지 않을 거에요. 예를 들어, 처음에 배열 size가 0이였는데, 1번째 요소에 추가하라는 쿼리가 들어왔다고 생각해 봅시다. 그러면, 추가 후에 vaild한 위치는 [0, 0] 구간에 속한 정수입니다. 1은 [0, 0] 구간과는 벗어납니다.
이 경우에는 무시를 하기 위해서 20번째 줄이 있습니다. 다음에 size가 capacity인 경우, 하나 추가를 하면, capacity를 넘어갈 거에요. 그렇기 때문에, grow를 호출합니다. 이렇게 전처리를 한 후에 어떻게 하면 좋을까요?
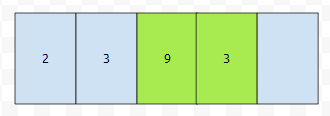
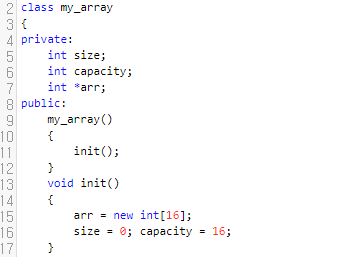
size가 4이고, lo가 2인 경우를 생각해 봅시다. lo에 1을 추가한다고 하면, add 메서드를 호출한 후에, [2, 3, 1, 9, 3]이 되어야 할 겁니다. 그러면 연두색 부분을 오른쪽으로 1칸 밀면 되는데요. 뒤에 있는 것부터 밀어주면 될 거에요. 오른쪽으로 1칸씩. 그렇다면 size-1부터, lo까지 i의 값을 하나씩 감소시키면서 우측으로 밀어버리면 되겠네요.
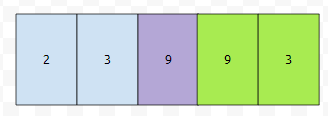
다음에 보라색 부분에 1을 넣으면 됩니다.
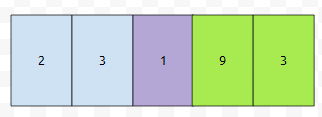
size도 하나 증가시키면 좋을 듯 싶네요. 코드를 보겠습니다.

24 ~ 25번째 줄은 기준 위치로부터 뒤에 있는 원소들을 뒤로 1칸씩 밀어버리는 코드입니다. 뒤로 다 밀어버렸다면, lo번째에 num을 넣고, size를 하나 증가시키면 됩니다.
삭제는 어떻게 하면 될까요? 사실 1, 2, 3번 쿼리만 들어온다면, 2번만 생각해도 사실 별 문제는 없습니다. 왜냐하면, insert가 되는 원소는 최대 Q개이기 때문입니다. lo번째 원소를 지우는 것은, lo번째 원소에서 lo번째 원소를 지우는 쿼리로 생각한다면, 아래와 같이 쓸 수 있습니다.

그러면, 구간을 지우는 함수를 구현해 보도록 하겠습니다. 단, invaild한 구간이 들어오면 무시를 하도록 하겠습니다. vaild한 구간이 들어왔다고 한다면 어떻게 하면 될까요? 사실, 임시 배열을 생성하는 방법도 있습니다. 그런데, 더 좋은 방법이 있습니다.

지워야 하는 구간을 초록색, 그렇지 않은 구간은 하늘색으로 표시해 보았습니다. 1번째 원소를 보았을 때, 하늘색입니다. 지워야 하는 구간이 아니기 때문에, arr[pos]에 arr[i]를 넣습니다. 다음에 pos랑 i를 하나씩 증가시킵니다.
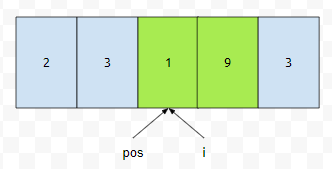
그 다음에, i가 가리키는 원소는 제거해야만 하는 원소입니다. 이 때에는, i값만 증가시킵니다. 대입 연산도 하지 않습니다.
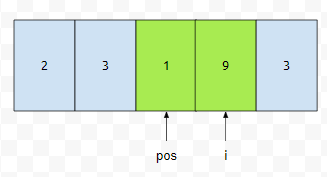
다음에 i는 3번째 원소를 가리키는데요. 마찬가지입니다. 그렇기 때문에 i만 증가시킵니다.
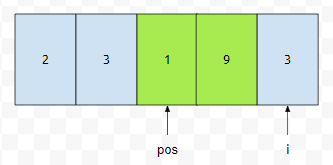
이 경우는 어떤가요? i가 가리키는 원소는 지워야 할 원소가 아닙니다. 따라서, arr[i]의 값을 arr[pos]에 넣고, pos와 i를 하나 증가시킵니다.
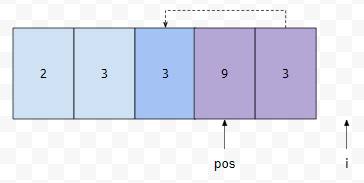
i가 배열의 끝에 도달했기 때문에, 끝내시면 됩니다. 보라색 부분만 제거를 하면 되는데요. size 값은 pos값과 같다는 사실을 이용하면 어렵지 않게 해결하실 수 있습니다.

제가 위에서 설명했던 것들을 코드로 구현하면 위와 같습니다. 이것은 삭제해야 할 구간이 띄엄 띄엄 있을 때, 굉장히 유용하게 쓸 수 있는 방식입니다. 그런데, 위의 문제 상황에서는 띄엄 띄엄 있지도 않고, 구간 하나만 삭제하면 된다고 했습니다. 그러면, 여기서 조금 더 optimize를 할 여지는 없을까요? 사실, s부터 e까지 지운다고 했을 때, 0번째부터 탐색을 할 필요가 없습니다.

s번째부터 탐색하면 됩니다. 그러면, O(size)만큼 탐색하던 것을, O(size-s)만큼만 탐색하게 됩니다. 만약에 s가 size에 매우 가깝다면, 이 차이는 꽤 극단적으로 다가올 수 있을 겁니다. 그런데, 여기서도 비효율적인 부분이 남아 있습니다. 굳이 i값을 s부터 탐색할 필요가 있을까요? e+1부터 탐색하면 안 되나요?

그래도 됩니다. 즉, [e+1, size-1] 구간만 적당히 잘 복사하면 됩니다. 전체 소스코드는 링크를 보시면 됩니다.
'구현' 카테고리의 다른 글
| 백준 배열 돌리기 4 : 요소별로 나누면 어렵지 않다. (6) | 2020.04.14 |
|---|---|
| 큰 수를 어떻게 좌표 압축하면 좋을까요? (6) | 2020.03.04 |
| 코딩테스트에 나올 만한 백트래킹 쉽게 정복해 봅시다. (0) | 2020.01.28 |
| 백준 16768 : 뿌요뿌요 게임을 구현해 봅시다. (10) | 2020.01.27 |
| 코딩 테스트 통과를 위한 세세한 제한 조건 잘 읽기 (10) | 2020.01.03 |


최근댓글