안녕하세요. 오늘은 큰 수를 어떻게 좌표 압축을 하는지 알아보도록 하겠습니다. 대소 비교하는 방법도 익힐 겸. 백준 17126을 보면, 일반적인 그냥 쿼리 문제인 것 같아 보입니다. key의 조건을 보기 전 까지는요.

여기서, 모든 key 값의 범위는 1이상 (10^99)-1 이하입니다. 여기서 좌표 압축을 한다는 것은, 들어오는 Key나, 중요한 수에 대해서 순서를 재정렬 하는 것을 의미하는데요. 그러려면, sort가 되어야 할 거에요. 정렬을 하기 위해서는 두 큰 수를 compare 해야 합니다. 이것을 어떻게 해야 할까요? 일단 long long 형이나, int형, 그리고 __int128로는 cover가 되지 않음은 자명합니다.
먼저 어떤 수 A가 B보다 작다면 무엇을 만족해야 하는지 생각해 봅시다.

자릿수별로 배열을 만들어서 처리를 하면 조금 더 나을 듯 싶네요. 그러면 대략적인 자료구조는 아래와 같이 설계해도 무난할 거에요.

그 다음에, 정렬을 할 건데요. c++의 string은 기본적으로 sort를 할 때 코드값 사전순으로 정렬하게 되어 있습니다. '0'이 '1'보다 사전순으로 앞서고, '8'이 '9'보다는 앞섭니다. 그러면, 1자리 수를 저장한 벡터, 2자리 수를 저장한 벡터, 3자리 수를 저장한 벡터들을 모두 정렬을 한 경우, 아래와 같이 sort가 될 거에요.

sort를 했다면, 중복된 것을 제거해 봅시다. 이는 포인터 2개를 가지고 가능하다고 했는데요. 37, 37, 73을 예로 들어보겠습니다.

p와 lo가 있습니다. 둘 다 처음에는 처음 위치를 가리키고 있을 거에요.
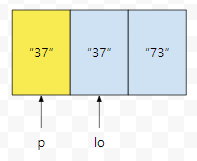
lo를 하나 증가시킵니다. 이 때, 이전 거 "37"과 lo가 가리키는 "37"이 같습니다. 따라서, 이 때에는 p를 증가시키지 않습니다.
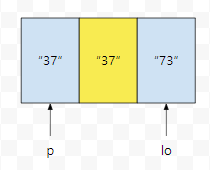
다음에 lo를 하나 증가시켰더니 "73"을 보고 있어요. 이는 이전 것의 "37"과는 다릅니다. 따라서, p를 증가시킨 다음에, v[p]에 v[lo]의 값을 넣습니다.

그러면 위와 같이 됩니다. 그 다음에 lo가 하나 증가하면 벡터의 끝에 도달했기 때문에 break를 걸면 됩니다. 우리는 p가 있는 곳까지를 취하면 됩니다. unique 메서드를 설명할 때 이야기 했던 내용들이네요. 그런데 왜 중복을 제거하느냐. 라고 물어보신다면, 1이 대충 2^20만개 있고, 2가 2^19개 있고, ... , 20이 2^0개 있다고 해 봅시다. 그러면 원소의 갯수가 대략 2^21개이니, 이진 탐색은 21번 가량을 찾아봐야 합니다.
그런데, 중복을 제거하면 그렇지 않아요. 1부터 20까지 단 20개만 있기 때문에, log(20) = 대략 4번 정도만 비교하면 됩니다. 이는 상수가 중요한 경우 크리티컬하게 다가오는데요. string 2개를 비교하고, 같은지 판단하고, 큰지 작은지 판단하려면, 기본적으로 string 둘 중에 작은 길이값 정도를 돌아봐야 합니다. 예를 들어, 100자리까지 올 수 있다면, 최악의 경우에는 string을 비교하기 위해서 100번의 loop를 돌아야 할 겁니다.

즉, 안 그래도 문자열 비교 때문에, compare 함수의 복잡도가 상수가 아닌 O(|string|)인 판에, 이진 탐색을 돌릴 때 범위를 좁혀나가는 연산을 더 많이 하게 된다면, 비효율적으로 동작할 수 있기 때문입니다.
con[zari]는 자릿수가 zari인 수들을 오름차순으로 정렬한 집합이라 해 봅시다. 그러면 "222"가 몇 번째 원소인지는 어떻게 찾는 것이 좋을까요? 일일히 100개의 con[zari]를 돌면서 lower_bound를 호출해 가면서 구한다.

각 자리마다 대략 log(n)회 정도의 이분 탐색을 수행한다. 100log(n). n의 값이 100만이라면, 찾는데만도 2000번. 더 좋은 방법이 없을까요? "222"는 세 자리 수이기 때문에, 사실 1자릿수와 2자릿수 정수는 볼 필요도 없습니다.
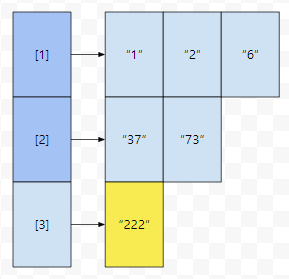
그러면 1자리 정수의 갯수 + 2자리 정수의 갯수 + 3자리에서 찾을 때 "222"가 몇 번째에 나오는지가 "222"가 실제로 몇 번째로 큰 수인지 구하는 수식일 겁니다. con[1], con[2], ... , con[100]은 중복이 제거되었기 때문에, 2의 자릿수를 가지는 정수의 갯수, 1의 자릿수를 가지는 정수의 갯수는 각각 con[1].size(), con[2].size() 등으로 구할 수 있습니다. con[1]과 con[2]가 vector였다면요.
각각 3과 2라면, 일단 "222"는 5보다는 확실히 크거나 같습니다. 다음에 3자리에서 찾을 때 "222"는 0번째에 있었어요. 즉 "222"는 3자릿수 중에서 제일 작은 수이므로, 3 + 2 + 1 = 6이 됩니다. 큰 수를 좌표 압축 하는 방법은 아래와 같습니다.

단, "z(1)...z(n)"은 집합 Set에 속해있다고 한다면, 요런 식으로 구하시면 됩니다. 그런데 100자리면. 일단 비교하는 것 부터 최악의 경우에 100회. 생각보다 많이 비효율인 듯 싶어요. 보통 String으로 많이 쓰기는 하는데..
사실 문자열로 큰 수를 저장하는 것 보다는 더 싸게 먹히는 방법이 있습니다. long long형이 18자리 자릿수는 cover가 될 수 있다는 점을 이용하면, 하위 자리수부터 18자리씩 끊어가면서 저장하면 됩니다. 예를 들어, 1 32573 22344 57182 11111이 들어왔다고 해 봅시다. 이것을 문자열로 저장하면 21 + 1 byte가 먹을 거에요. 이것보다 자릿수가 크거나, 같은 수와 비교할 때 21번의 비교를 해야 할 거에요.

그렇지만, 18자리씩 끊어서 저장하면, 단 2개의 long long형 배열로 cover가 된다는 것을 알 수 있어요. 100자리 정수라고 해도, 최대 5개의 long long형 배열만 있으면 cover가 됩니다. 따라서, 최악의 경우에도 100번 비교를 하는 게 아니라, 단 5번만 비교하면 됩니다. int 단위로 한다면, 9자리 단위로 쪼갤 수 있는데요. 이 경우에는 많아봐야 12번만 하면 되고요.
'구현' 카테고리의 다른 글
| 백준 원판 돌리기 : deque를 사용하면 쉽다. (0) | 2020.05.01 |
|---|---|
| 백준 배열 돌리기 4 : 요소별로 나누면 어렵지 않다. (6) | 2020.04.14 |
| 배열 원소 삽입 삭제 패턴만 익혀봅시다. (7) | 2020.02.16 |
| 코딩테스트에 나올 만한 백트래킹 쉽게 정복해 봅시다. (0) | 2020.01.28 |
| 백준 16768 : 뿌요뿌요 게임을 구현해 봅시다. (10) | 2020.01.27 |


최근댓글