문자열 처리를 할 때, 뒤에 있는 공백을 제거하거나, 뒤에 붙은 특정한 문자를 제거해야 하는 경우가 있습니다. 그 처리를 해야 할 때 어떻게 해야 할까요? 이번 시간에는 파이선의 strip 메서드에 대해 알아보겠습니다.
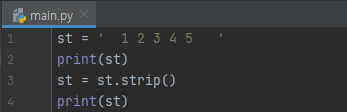
예제 1번을 보겠습니다. st는 앞과 뒤에, 공백과 탭으로 이루어져 있습니다. st.strip()를 수행해 봅시다.
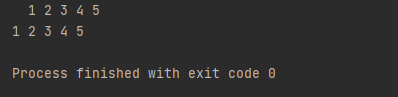
그러면 앞, 뒤에 붙은 공백, tab이 모두 제거 되었음을 알 수 있습니다. 이렇게 strip에 아무 인자도 오지 않은 경우에는 default로 화이트 문자들을 제거하게 된다고 문서에 명시되어 있습니다. 만약에, 앞과 뒤에 ., #, $하고, 화이트 문자가 들어오는 것을 지우려면 어떻게 하면 될까요?

이런 방법을 생각해 볼 수는 있습니다. strip를 2번 쓰면 된다. ., #, $을 기준으로 먼저 제거하고, 다음에 화이트 문자를 기준으로 제거합니다.
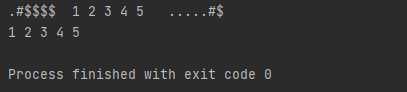
그러면, 요런 식으로 prifix가 .#$가 먼저 나오고 화이트 스페이스가 나오고, suffix가 화이트 스페이스가 나오고 .#$가 나오는 패턴은 제대로 동작합니다. 문제는, whitespace가 먼저 나와버리는 경우인데요.

이런 경우를 생각해 봅시다. 공백이 먼저 나온 경우. 이 때, 해당 방법은 제대로 동작할까요?

그렇지 않습니다. 이는 처음에 .#$가 prifix나 suffix에 나오면 제거를 하는 로직이였는데, 접두, 접미어가 공백이였기 때문에, 해당 메서드는 아무런 일을 하지 않았기 때문입니다. 그러면 어떻게 하면 될까요?
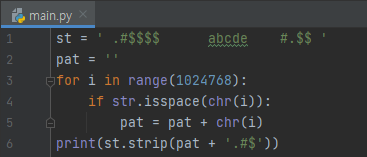
방법 중 하나는, whitespace를 모두 저장한 다음에, 그것이랑 .#$을 합치는 것입니다. 이것은 str.isspace로 할 수 있습니다. 계속 for 루프를 돌면서, pat에 화이트 문자들을 저장해 놓고, 6번째 줄에서 white 문자들이랑 ., #, $을 strip 메서드의 인자로 넣음을 알 수 있는데요.
이는 white space랑 ., #, $가 prifix나 suffix에 나오는 경우에 모두 제거합니다.

실행 결과는 위와 같습니다.

그러면 이런 패턴이 들어온 경우에도 제대로 동작할까요?

제대로 제거됨을 알 수 있습니다.
그러면 이 메서드의 복잡도는 어떻게 될까요? 시뮬레이션을 하면 쉽게 알 수 있습니다.

gen 메서드는 나중에 보고, 22번째 줄에 있는 for loop를 돌면서 하는 일을 봅시다. 뭔가 수행 시간을 측정합니다. 그리고, leni는 한 번 for문이 돌면 2배로 증가하는데요. 처음에 10만, 그 다음에 20만, 40만, 80만 순으로 증가함을 볼 수 있습니다.

gen 메서드를 보면, chrset에 한글 데이터를 모두 집어넣었습니다. 가부터 힣까지입니다. 다음에, 가부터 힣까지를 랜덤하게 뽑아서 n번 넣고, 아스키 코드로 32부터 126까지를 또 랜덤하게 뽑아서 100회에서 200회 가량 넣고, 다음에 n번을 또 가부터 힣까지 랜덤하게 뽑아서 넣습니다.
총 문자열의 길이는 2n + 100에서 2n + 200인 셈입니다. 그리고 gen에 들어온 n은 leni와 같으므로, 2leni + 100에서 2leni + 200의 길이의 ori가 생성됩니다. pat의 길이는 10000이 조금 넘습니다.
수행 시간을 보면, ori의 길이에 비례해서 증가함을 볼 수 있습니다. 그리고, 해당 문자가 pat에 속하는지를 O(|pat|)에 찾았다면, 저 시간이 나올 수 없을 겁니다. 왜냐하면, 마지막 테스트 케이스의 경우, ori의 길이가 80만이 넘어갔기 때문입니다. 만약에 O(|pat|)에 찾았다면 상당히 오래 걸렸을 겁니다.
0.x초가 걸렸다는 이야기는 해당 문자가 pat에 속하는지를 매우 빠르게 찾았다는 겁니다. 시간 복잡도는 O(|ori| + |pat|)으로 볼 수 있습니다.
'레퍼런스 > 예제' 카테고리의 다른 글
| java priority queue 예제 : 비교자만 잘 작성해 봅시다. (0) | 2021.02.22 |
|---|---|
| c++ copy 함수 : 내용을 복사할 때 쓴다. (0) | 2021.02.12 |
| java file 객체로 하위 폴더 파일들을 모두 찾아 봅시다. (2) | 2020.12.15 |
| python ord chr 함수 : 문자와 유니코드 포인트 (0) | 2020.10.31 |
| python join 메서드 : string을 append 할 때 쓴다. (0) | 2020.10.05 |


최근댓글