카톡방에서 이야기를 하다가, 파이선은 '각'을 유니코드 포인트를 나타내는 정수로 쉽게 변환할 수 있단 걸 알게 되었습니다. 그것을 토대로 규칙을 찾아서 분리한다. 괜찮은 방법입니다. 일단 문자를 문자 번호로 변환하는 것부터 해야 겠는데요. 이럴 때 쓸 수 있는 것은 ord 함수입니다.
ord 함수는 유니코드 문자가 하나 주어지면, 그것을 코드 포인트로 바꾸는 함수입니다.

다음을 수행해 보겠습니다. Cpython 3.x대에서 수행하였습니다.

44032가 나옵니다. '가'의 유니코드 포인트는 AC00입니다.

그리고 결과값으로 나온 44032를 2진수로 변환해서 HEX 값으로 보면 AC00임을 알 수 있습니다. 그러면, '각'과 '값' 등은 어떤 값으로 할당이 되어 있을까요? 이 문서를 보시면, 사전순으로 코드값이 연속해서 할당이 되어 있음을 알 수 있습니다.

그림으로 그리면 위와 같이 됩니다. 질문, 해당 문자가 ㄱ을 초성으로 쓰는지, ㄴ을 초성으로 쓰는지 등은 어떻게 알 수 있을까요? 연속이 되어 있다는 의미를 잘 생각해 보면, '까'에서 '가'의 차이는 초성이 ㄱ인 가짓수와 같다고 볼 수 있습니다.

이 값은 588이 나옵니다. 그러면 44032로부터 ord(ch)값이 얼마만큼 떨어졌는지 계산한 뒤에 588로 나눈 몫을 구해보면 되지 않을까요? 일례로 '낮'이라는 문자는

45230이 나옵니다. 45230 - 44032 = 1198입니다. 1198을 588로 나누면 몫이 2인데요. 이는 초성이 'ㄴ' 이라는 의미입니다. 하나 더 질문. 아스키 코드에 속하는 문자들도 제대로 나올까요? 예를 들어 '0'이나 알파벳 대문자, 소문자 같은 것들. '0'이나 'A', 'a'와 같은 문자에 대해서도 코드 값을 구할 수 있습니다.
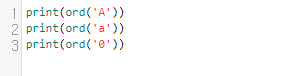
위 코드를 실행해 봅시다.

실행 결과는 65, 97, 48입니다. 이는 'A', 'a', '0'이 0000 - 0FFF에 속하기 때문입니다.
반대로, chr 함수는 유니 코드 값을 문자로 돌려주는 함수입니다. 아래 코드를 돌려 보겠습니다.
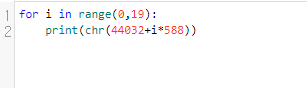
44032 + 588*i의 유니코드 값에 해당하는 문자를 출력해 보도록 하겠습니다.
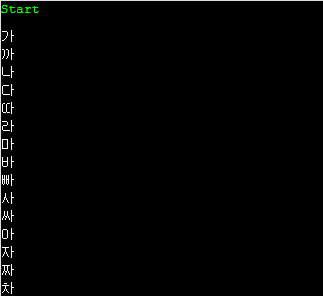
그러면, '가', '까', '나', ... 순서대로 나타남을 볼 수 있습니다. 글의 내용을 정리해 보면 chr하고 ord는 다음과 같은 관계에 있음을 알 수 있습니다.

이 관계만 이해하시면 됩니다.
'레퍼런스 > 예제' 카테고리의 다른 글
| 파이썬 strip 함수 : suffix와 prifix에 있는 특정 문자들을 제거할 때 유용하다. (2) | 2021.02.05 |
|---|---|
| java file 객체로 하위 폴더 파일들을 모두 찾아 봅시다. (2) | 2020.12.15 |
| python join 메서드 : string을 append 할 때 쓴다. (0) | 2020.10.05 |
| 항상 flush를 해서 느린 c++ endl (4) | 2020.08.18 |
| java properties 클래스 : txt 파일로부터 속성값들을 읽어봅시다. (4) | 2020.06.25 |


최근댓글